本教程全程使用windows系统
此项目程序、模型默认安装到C盘,请保证存储空间充足
模型可以存到其他盘,下次再做教程😀
在人工智能领域,大型语言模型(Large Language Models, LLMs)以其强大的文本生成和理解能力,正逐步改变我们与自然语言交互的方式。然而,这些模型的运行往往需要庞大的计算资源和复杂的部署流程,使得许多用户望而却步。幸运的是,Ollama的出现为我们提供了一个简单而高效的解决方案。
Ollama简介
Ollama是一个功能强大的开源工具,它专注于简化大型语言模型在本地环境的部署和运行过程。通过提供简洁明了的命令行界面和丰富的功能选项,Ollama让即便是没有深厚技术背景的用户也能轻松上手。无论你是研究人员、开发人员还是普通用户,Ollama都能为你提供强大的支持。
下面来教你们进行安装吧
第一步
从ollama官网下载安装程序

点击Download下载程序
下载好后点install安装就行
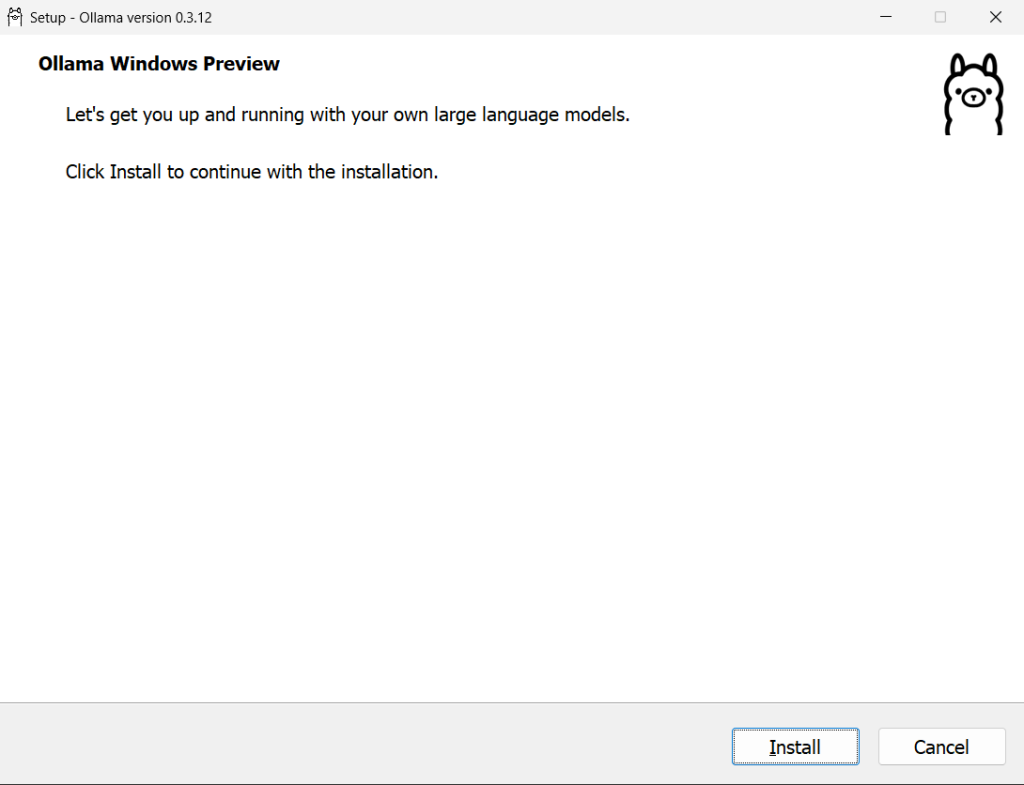
安装好后可以看到程序在后台运行就可以继续下一步了

第二步
win+r键打开运行输入cmd打开命令提示符或者打开win菜单搜索cmd打开

在cmd里面输入 ollama pull <模型名> 拉取模型
拉取什么模型可以看官方网站上的模型库
我这里拉取的是qwen2.5:0.5b(因为在做演示,他比较小,拉取快)
建议大家拉取最新的llama3.2模型,冒号后面跟着的是模型参数,建议自己电脑16g运行内存的用不超过8b的模型,具体这个模型有多少b的参数可供拉取看官方给的库
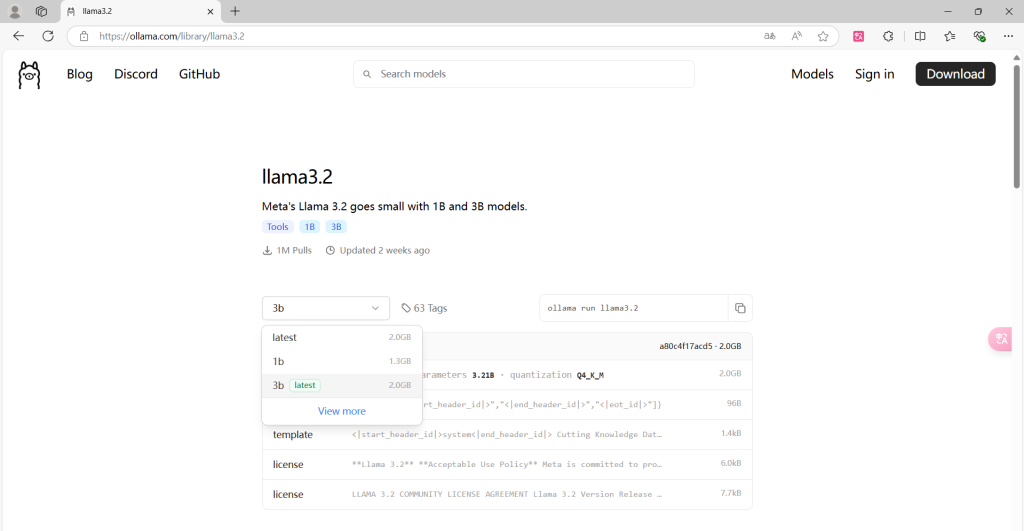
可以看到llama3.2目前最新就是3b,拉取的命令就是 ollama pull llama3.2:3b
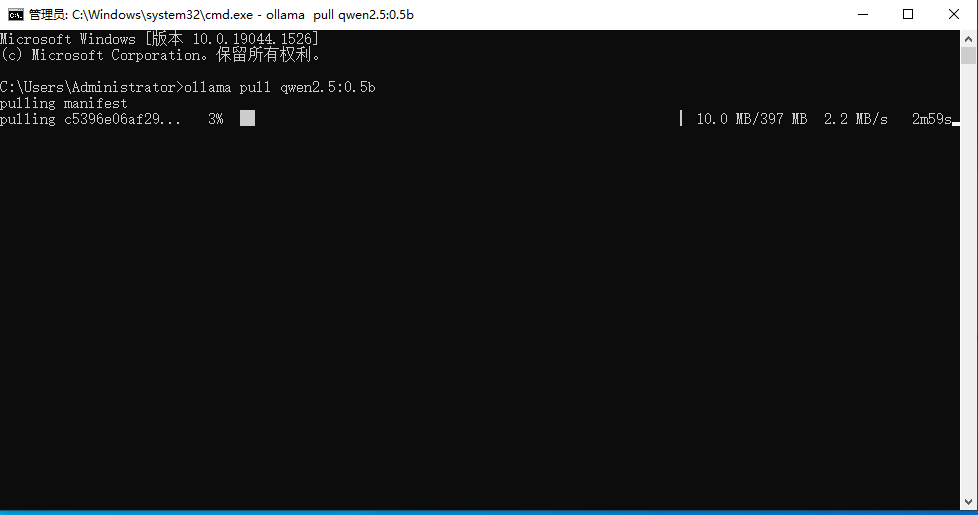
这样就是在拉取了,等他拉取完成就可以继续了
拉取完成用命令 ollama list 就可以看到当前的电脑里面有什么模型
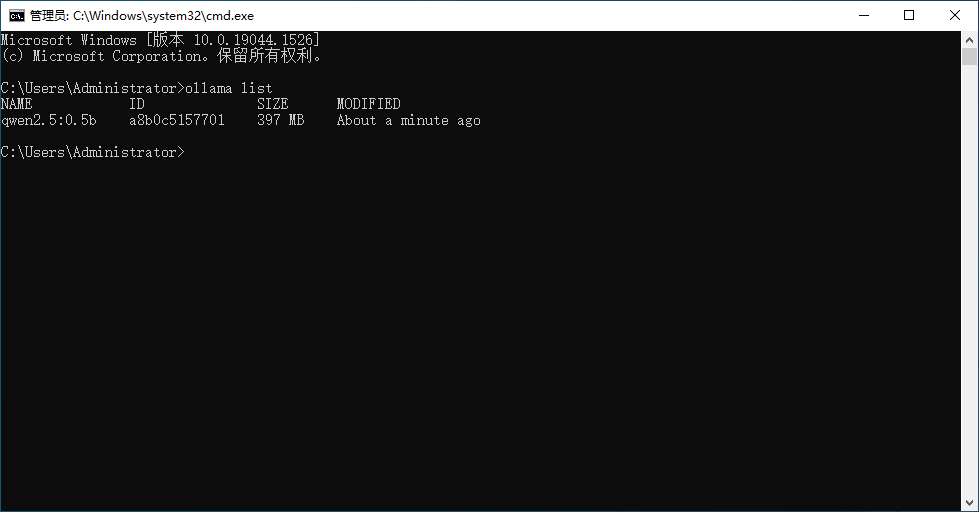
这里可以看到我刚刚拉取的qwen2.5:0.5b的模型
最后一步
运行命令 ollama run <模型名> 就可以运行本地的AI了
比如这样
下面我们来问他一个问题测试一下
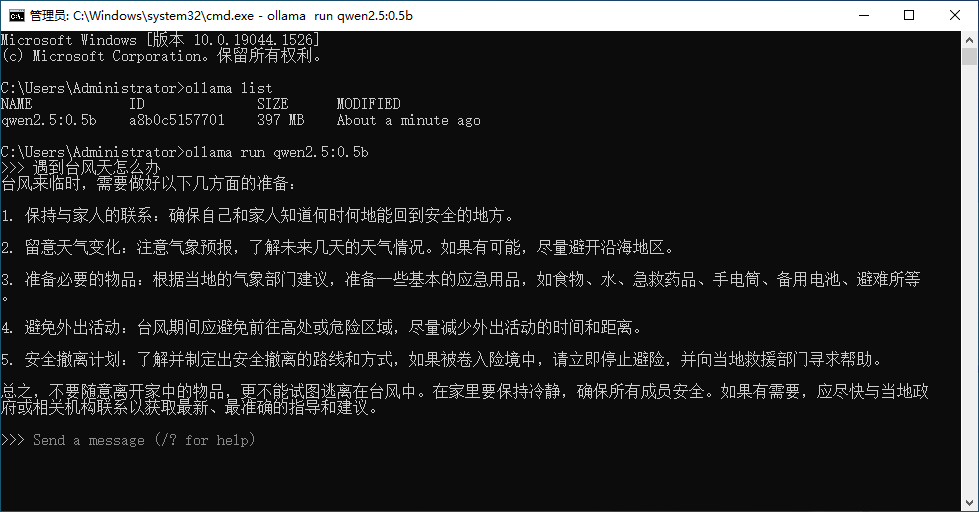
可以看到反应还是很快的
以上就是本地部署ollama模型的方法,当然这样的使用方法是不好用的,只能用来问答
后面我会出调用ollama的可视化webui教程,支持网络搜索、上传文件、微调、知识库的聚合项目,部署起来也相对简单,大家敬请期待!!!
可以使用”mkdir /J <被代替的路径> <实际存储位置>”这个命令将模型的文件夹链接到其他盘里,命令的详细信息可以参考 https://www.icoa.cn/a/910.html